经典计算机指令的先后顺序往往也意味着逻辑关系,我们总是会直觉性的认为程序指令是从上到下一个个执行的。虽然这种直觉在很多场景下是没有问题的,但真相不止于此。如果你对memory order这个概念还不是太了解,下面这个test应该会带来一点“惊喜” ^_^
// 代码段1
// store-buffering校验
P0(int x0, int x1)
{
int r2;
WRITE_ONCE(x0, 2); r2 = READ_ONCE(x1);
}
P1(int x0, int x1)
{
int r2;
WRITE_ONCE(x1, 2); r2 = READ_ONCE(x0);
}
exists (1:r2=0 / 0:r2=0)
这个test的形象使用场景是——两个线程各自持有一个buffer,业务逻辑是写一次自己的buffer后读一下对方的buffer。P0和P1分别代表在两个处理器上跑的逻辑(刚开始x0,x1所指向的内存都是0),两个函数分别跑完之后,存在P0的r2等于0、P1的r2也等于0的可能性(即使在x86这种比较老实巴交的cpu上),即两个线程跑完各自逻辑后,都没有读到对方写入buffer的数据。怎么解释这个现象呢?那就好搬出主角——“memory order”~ 内存顺序这个概念是和计算机体系结构紧紧关联的。在最简单的计算机架构中,memory order其实不需要费心的。但是在更现代的计算机架构中,memory order就成为一个重要概念了。比如上边这个test,其实就与cpu的cache、store buffer有密切关系。
Cache结构
较现代化的CPU都有高速缓存,如下表所示,高速缓存的访问速度要比主存快两个数量级,这是个非常巨大的优势。但是有了缓存,缓存一致性的问题也就产生了。当多个CPU以非共享方式访问(至少一个有写入)同一个位置的内存时,就会遇到一致性的问题。

缓存访问速度对比
而对一般的SMP(symmetric multiple processors)来说,其对应的缓存架构如下图所示:
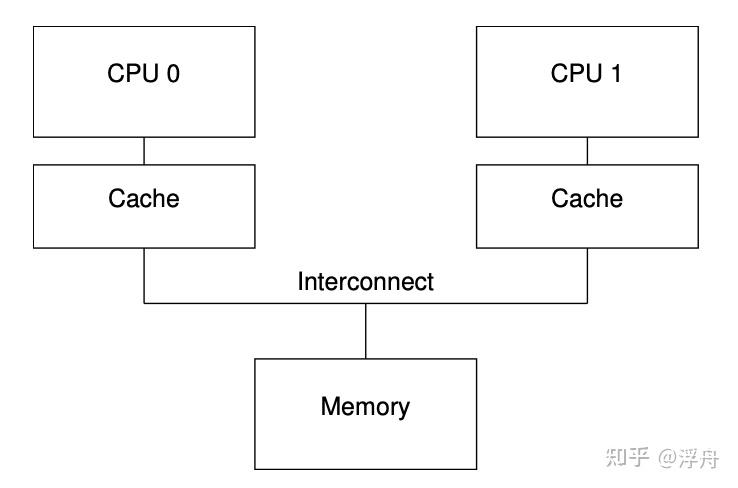
不同CPU分别有自己独立的cache单元,而不同的cache单元又相互连接在一起,最后再统一连接到内存总线上。cache单元之所以要相互连接到一起,其实是就是为了解决数据一致性的问题。倘若不同的cache单元各自单独连接到主存,则非常容易出现各个cache单元中对同一内存地址的数据不一致、而且最终一致性都不能保证。
MESI缓存一致性协议
为了解决MP系统的缓存一致性问题,缓存一致性协议就应运而生了,比如MESI协议。MESI存在”modified”,”exclusive”,”shared”和”invalid”四种状态,协议可以在一个指定的缓存中应用这四种状态。因此,协议在每一个缓存行中维护一个两位的状态”tag”,这个”tag”附着在缓存行的物理地址或者数据后。我之前有写过一篇相对详细的文章,为了文章整体的完整性和结构,这会简单的提一点重要概念。
- 处于“ modified” 状态的缓存行是由于相应的 CPU 最近进行了内存存储。并且相应的内存确保没有在其他 CPU 的缓存中出现。
- “exclusive”状态非常类似于“ modified” 状态,唯一的例外是缓存行还没有被相应的 CPU 修改,这表示缓存行中的数据及内存中的数据都是最新的。
- 处于“ shared” 状态的缓存行可能被复制到至少一个其他 CPU 缓存中,这样在没有得到其他 CPU 的许可时,不能向缓存行存储数据。
- 处于“ invalid” 状态的行是空的,换句话说,它没有保存任何有效数据。
MESI协议的核心部分就是MESI消息以及状态转移图。其中MESI消息就是cache单元以及内存控制器之间的通信协议,而MESI状态机则是缓存状态的记录方式。MESI消息有如下种类:
- Read:当CPU在自己的cache中没有发现需要的物理地址,就会发送一条“READ”消息,该消息包括缓存行需要读的物理地址。
- Read Response: 顾名思义,”Read Response”消息是回复“Read”消息的。“Read Response”消息是由内存或者其他CPU缓存提供的。如果其他缓存请求一个处于“modified”状态的数据,则本地缓存必须提供“Read Response”消息。这个很容易理解,别的CPU在请求本地缓存中的数据,而这份数据还没有刷新到内存,所以必须告诉其他CPU该数据的最新值。接收到”Read Response”消息后,该数据的缓存状态就由”invalid”变成了”share”或者”exclusive”,这取决于”Read Response”的提供者是内存还是其他CPU缓存。
- Invalidate:“ invalidate” 消息包含要使无效的缓存行的物理地址。其他的缓存必须从它们的缓存中移除相应的数据并且响应此消息。当CPU要对一个变量进行写操作,而此变量处于只读状态(share),就需要发送“invalid”消息。由于一个变量被多个CPU缓存,所以单个CPU的改写会造成缓存不一致,所以在写之前必须告诉其他CPU你们缓存的值马上就要过时了。接收到”invalidate”消息的CPU就会把本地缓存中的对应数据无效掉。
- Invalidate Acknowledge:一个接收到“invalidate”消息的 CPU必须在移除指定数据后响应一个“invalidate acknowledge”消息。这个消息就是告诉“invalidate”消息的提供者“我已经知道你要更改这个数据了,我放弃使用自己缓存中的拷贝!”
- Read Invalidate:”read invalidate”消息包含要缓存行读取的物理地址。同时指示其他缓存移除数据。因此,它包含一个”read”和一个”invalidate”。“read invalidate”也需要“read response”以及”invalidate acknowledge”消息集。“Read Invalidate”消息的发送时机有两个:第一个是CPU对一个数据进行原子读写操作,但是该数据没有在本地CPU的缓存中,在其他CPU缓存中可能有该数据的拷贝。所以它需要发送一条“Read Invalidate”消息,它不仅需要读取该数据的最新值,还要无效掉其他的CPU缓存(它马上就要改写该数据)。
- Writeback:“writeback”消息包含要回写到内存的地址和数据。这个消息允许缓存在必要时换出“modified”状态的数据以腾出空间。消息的发送时机是,CPU把本地缓存中的数据刷新到内存中,而该数据是share状态(只读),它需要告诉其他CPU”我不再使用这些缓存数据了”
MESI的状态机转移图如下所示,其中方块形的定点就是四种缓存状态、a~l这些边则是对应状态转移(一般是读写操作或者收到MESI消息触发的)。详细讲解需要的篇幅比较多,这里就不赘述了。
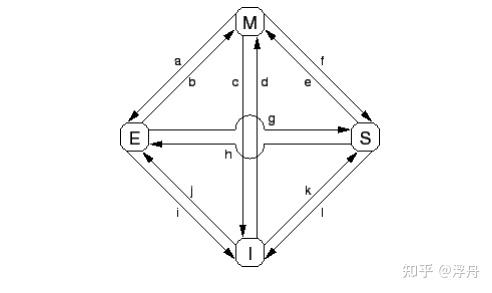
MESI协议状态转移图
Store Buffer结构
导致缓存一致性的根本原因还是写入操作,所以各种硬件优化都会紧紧围绕写入操作的流程。按照MESI协议,一次典型的写入可以展示为以下形式,箭头是时间轴: 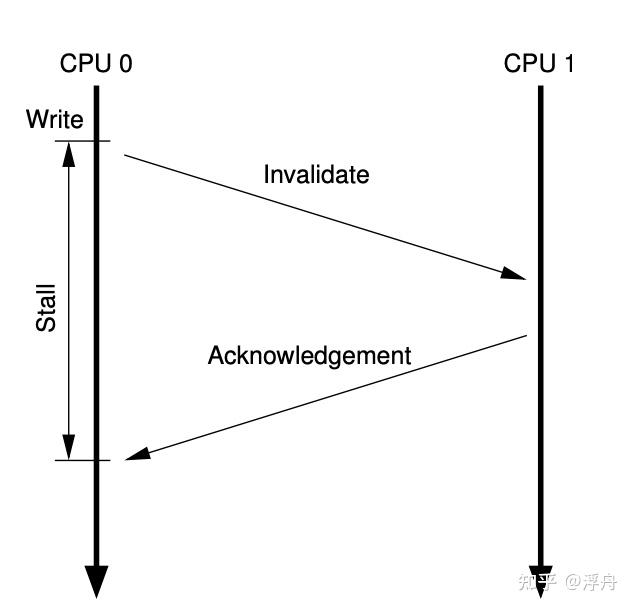 开始的时候,同一个缓存行被两个CPU共享。然后CPU 0发射了一个写入指令,该指令会改动共享的缓存行,所以CPU 0(包括其cache结构)会给CPU 1发送一个Invalidate消息,CPU 1接收到这个Invalidate消息之后就会把相应的内存缓存行无效掉,然后给CPU 1回复一条Invalidate Ack消息。CPU 0收到Invalidate Ack之后就把自己的缓存行置为“Modified”。 虽然上面这段流程发生在很小的SMP上,但其实和网络程序是非常类似的。假设CPU就这样一个一个的执行指令,那它的模式就非常类似于BIO(Blocked IO)。一般来说BIO的吞吐量是比较差的,通常都会使用Non-blocked IO或者AIO提高吞吐量。对于SMP来说,也是可以采用类似的优化方案——把写入的后续操作放到一个队列中来异步形式的完成,这样就少了一段等待的时间。这样的硬件结构如下图所示:
开始的时候,同一个缓存行被两个CPU共享。然后CPU 0发射了一个写入指令,该指令会改动共享的缓存行,所以CPU 0(包括其cache结构)会给CPU 1发送一个Invalidate消息,CPU 1接收到这个Invalidate消息之后就会把相应的内存缓存行无效掉,然后给CPU 1回复一条Invalidate Ack消息。CPU 0收到Invalidate Ack之后就把自己的缓存行置为“Modified”。 虽然上面这段流程发生在很小的SMP上,但其实和网络程序是非常类似的。假设CPU就这样一个一个的执行指令,那它的模式就非常类似于BIO(Blocked IO)。一般来说BIO的吞吐量是比较差的,通常都会使用Non-blocked IO或者AIO提高吞吐量。对于SMP来说,也是可以采用类似的优化方案——把写入的后续操作放到一个队列中来异步形式的完成,这样就少了一段等待的时间。这样的硬件结构如下图所示:
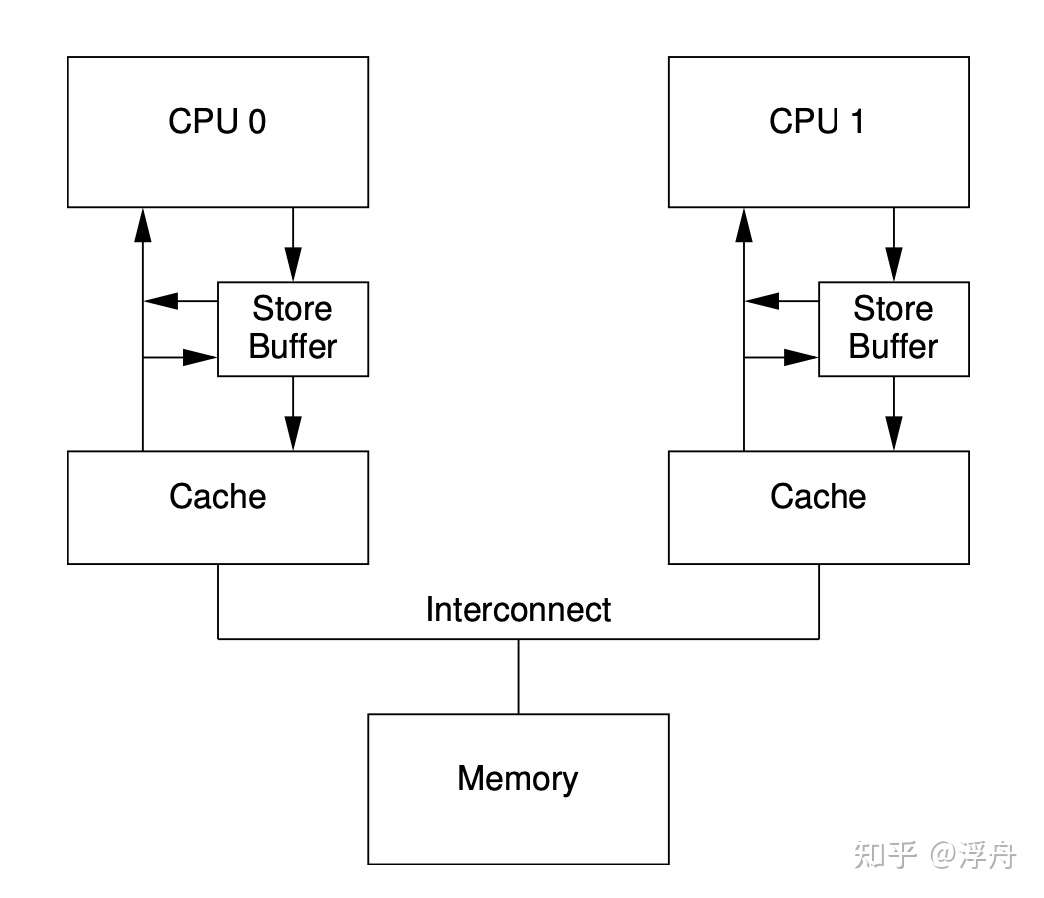
带Store Buffer的SMP结构
值得注意的一点是这个图也体现了store forward的结构(为了实现store buffer和cache之间的一致性),这里不赘述。 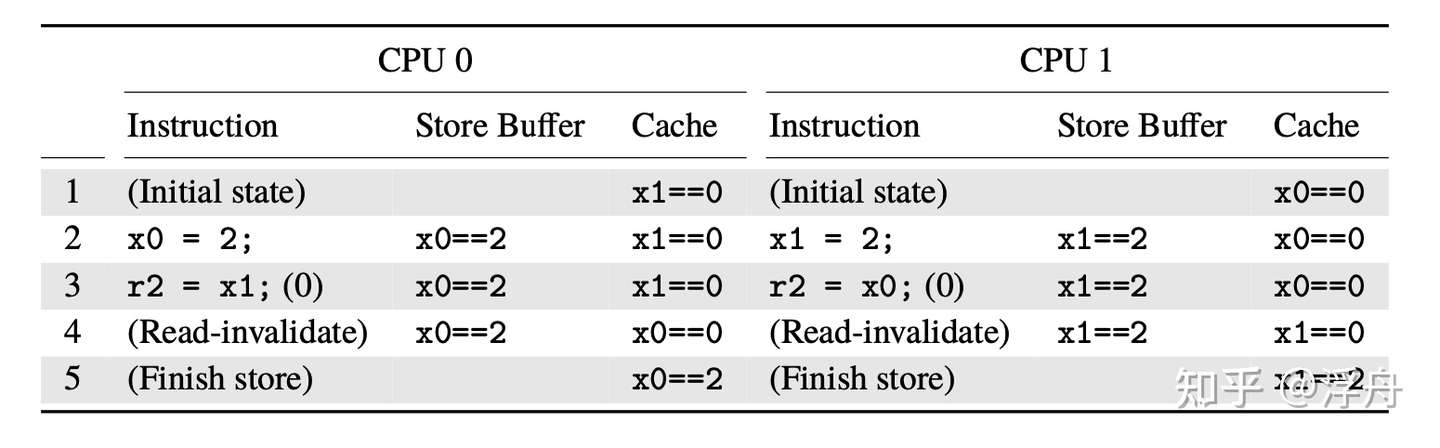 store buffer引起的校验失败 现在再回头看开头提到的store buffer校验例子,就会发现不难理解了。step 2的写入操作其实只是放到了store buffer里面,step 4才真正开始执行写入操作,CPU 0和CPU 1之间相互invalidate对方的缓存数据,然后最终完成了写入操作。然而step 3的读操作由于有缓存的原因,非常快速的就完成了。从结果上来看,相当于store~load的操作顺序被调整为了load~store。事实上,几乎所有的现代CPU都会做这种优化。
store buffer引起的校验失败 现在再回头看开头提到的store buffer校验例子,就会发现不难理解了。step 2的写入操作其实只是放到了store buffer里面,step 4才真正开始执行写入操作,CPU 0和CPU 1之间相互invalidate对方的缓存数据,然后最终完成了写入操作。然而step 3的读操作由于有缓存的原因,非常快速的就完成了。从结果上来看,相当于store~load的操作顺序被调整为了load~store。事实上,几乎所有的现代CPU都会做这种优化。
Store Buffer与Memory Barrier
与上文中的代码片段类似,下面这个用例在主流的SMP(有store buffer结构)上基本都有可能失败。
// 代码段2
int a = 0, b = 0;
void foo(void) {
a = 1;
b = 1;
}
void bar(void) {
while (b == 0)
continue;
assert(a == 1)
}
我们把可能的失败执行过程分析如下: 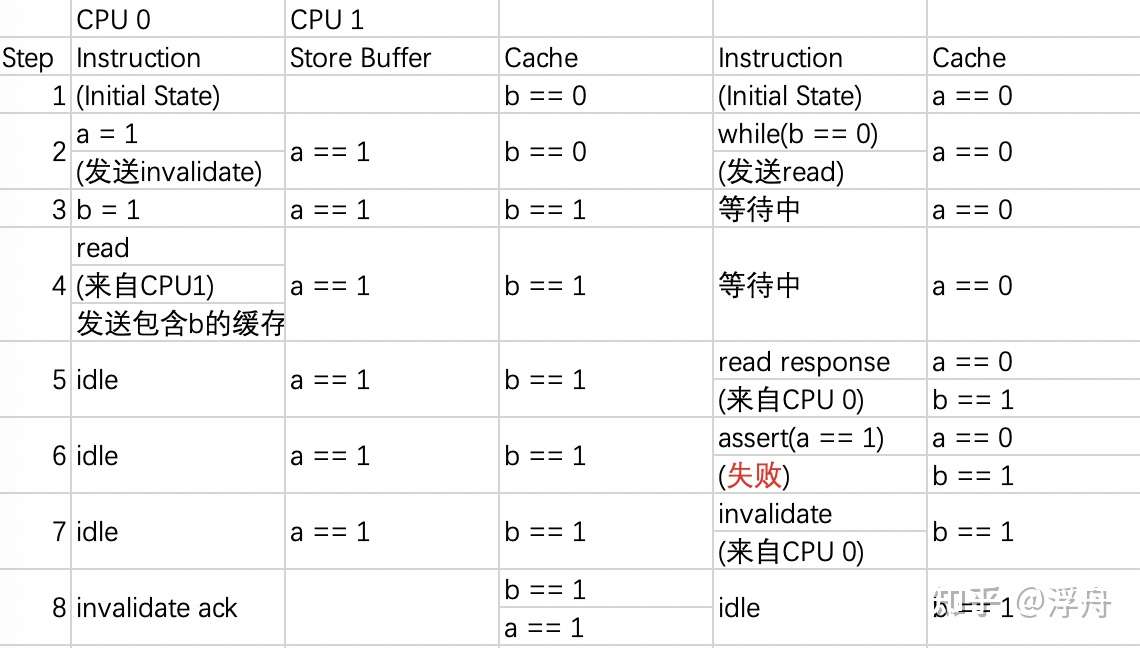 代码段2可能的失败流程 比较明显的看出来,就是这个store buffer在捣鬼,导致a、b写入的先后顺序变得不可靠了。为了解决这个问题,内存屏障(memory barrier就应运而生了)。memory barrier是一种特殊的指令。为了便于理解,我们先讨论作用于store buffer的内存屏障。这种内存屏障的指令的效果就是强制CPU在执行后续写入指令之前,把store buffer中现有的写入都执行完毕。 使用内存屏障改进上面的代码,可以得到如下的形式:
代码段2可能的失败流程 比较明显的看出来,就是这个store buffer在捣鬼,导致a、b写入的先后顺序变得不可靠了。为了解决这个问题,内存屏障(memory barrier就应运而生了)。memory barrier是一种特殊的指令。为了便于理解,我们先讨论作用于store buffer的内存屏障。这种内存屏障的指令的效果就是强制CPU在执行后续写入指令之前,把store buffer中现有的写入都执行完毕。 使用内存屏障改进上面的代码,可以得到如下的形式:
// 代码段3
int a = 0, b = 0;
void foo(void) {
a = 1;
smp_mb();
b = 1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1)
}
则执行的流程会变成下面这样: 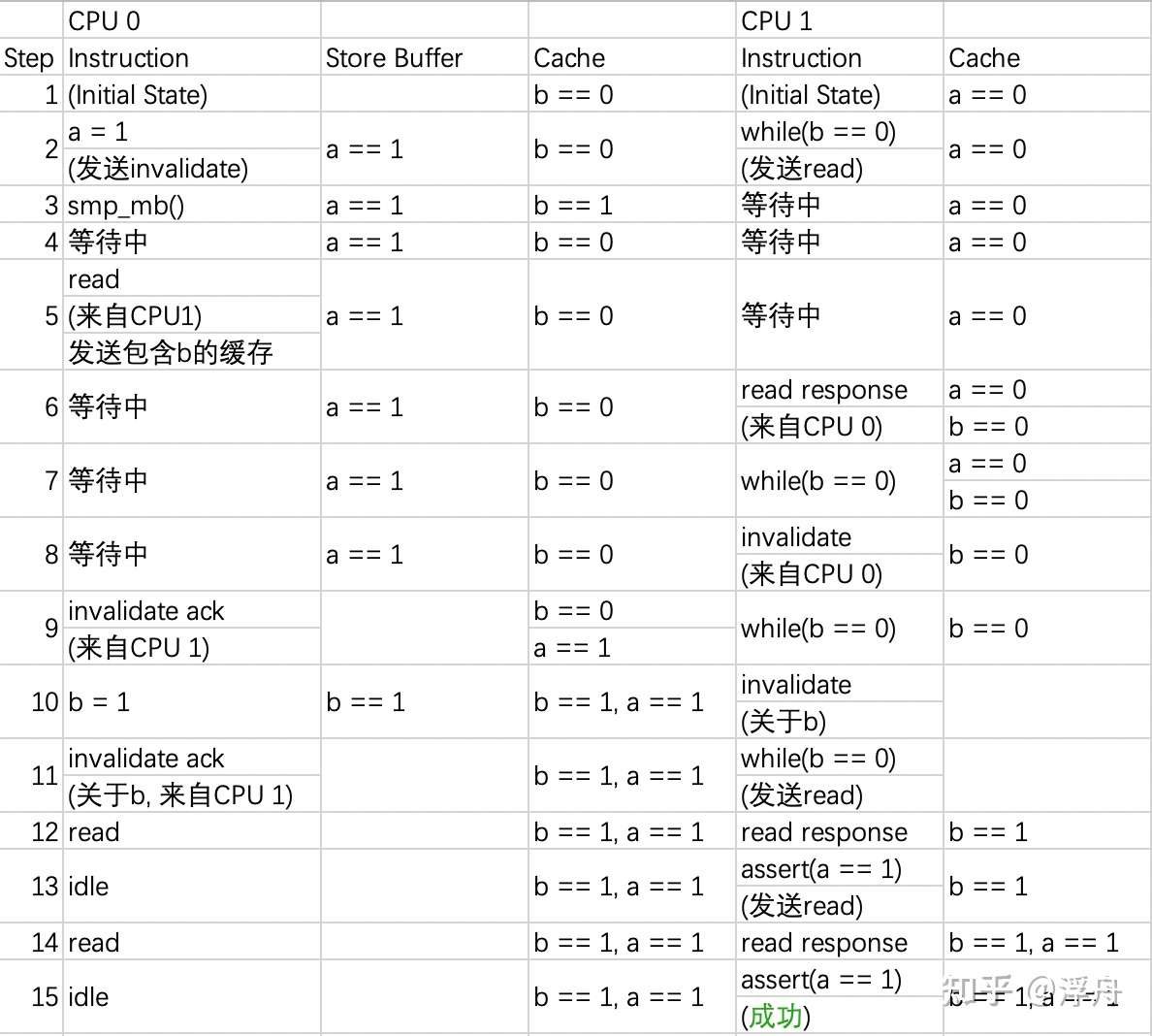 代码段3的流程
代码段3的流程
Invalidate Queue结构
前面仅仅从写入方的角度分析了吞吐量的提升方案,其实还有另外一个角度——读取方。考虑一次CPU的写入操作,执行时可能会向其他CPU发送invalidate消息。如果短时间内有多个CPU执行写入操作(针对不同的缓冲行),则某一个CPU会在短时间内收到非常多的invalidate消息。如果是同步处理的话,有的CPU就会被阻塞了。为了优化这个点,一个新的硬件结构被提出来了,这就是Invalidate Queue。CPU 0给CPU 1发送invalidate消息的时候,只需要把消息投递到CPU 1的Invalidate Queue这个队列就好。此时的SMP结构如下: 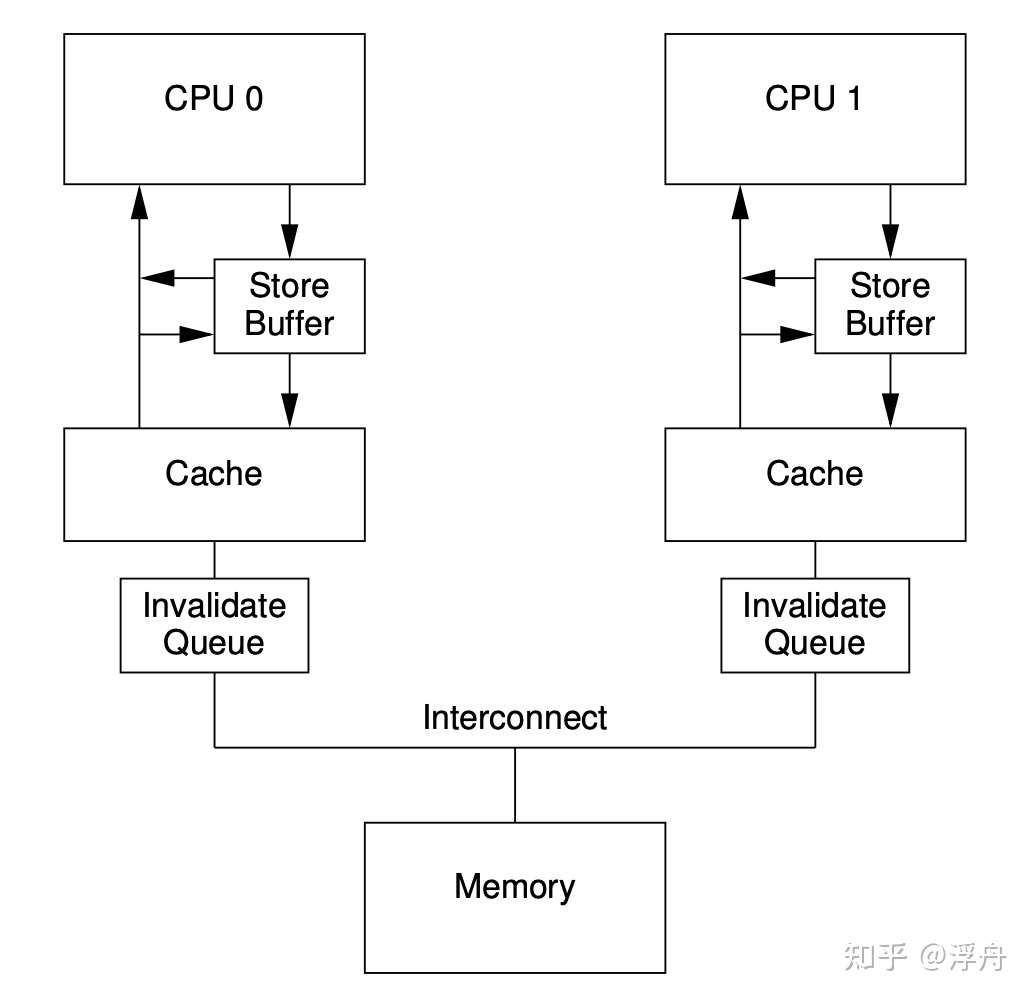
带Invalidate Queue的SMP结构
如果说前面的store buffer结构已经引入了一些理解上的“麻烦”,那Invalidate Queue也不是省油的灯。上边的那段针对Store Buffer的改进版代码,它真的就很安全了吗?NO!很不幸,这个断言在有Invalidate Queue的CPU上还是有可能失败。 其实原因和Store Buffer引起的问题非常类似,依然是异步的问题。Invalidate消息会被放到Invalidate Queue里面,导致一些cache内容没有及时的无效掉。而在这个中间时间内,CPU就可能读到旧的值,继而导致“乱序现象”。 原因类似导致解决方法也非常类似,就是增加读取的memory barrier指令。这种“读”内存屏障的指令的效果就是强制CPU在执行后续读取指令之前,把Invalidate Queue中现有的invalidate任务都处理完毕。 其实非常容易理解,把Invalidate Queue里面的Invalidate消息处理完毕之后,cache里面的内容就是很新的版本了,此时再去读取就能保证“内存顺序”了。则代码会成为下面这样:
// 代码段4
int a = 0, b = 0;
void foo(void) {
a = 1;
smp_mb(); // 可以优化为只作用于store buffer
b = 1;
}
void bar(void) {
while (b == 0) continue;
smp_mb(); // 可以优化为只作用于invalidate queue
assert(a == 1)
}
Memory Fence(barrier)与程序设计
虽然各家CPU都提供了内存屏障的汇编指令,但是如今大家都用高级语言做程序设计,并且希望同样的代码可以兼容不同的硬件平台。所以如今的native语言也引入了memory order的概念,而memory order在高性能程序设计、无锁编程场景中就显得比较重要的了。
// 代码段5 没考虑load-store重排序
typedef enum memory_order {
memory_order_relaxed, // 等于啥都不干
memory_order_consume, // 根据数据依赖关系插入内存屏障,实验性
memory_order_acquire, // 利用读取内存屏障,作用于上文中的invalidate queue
memory_order_release, // 利用写入内存屏障,作用于上问中的store buffer
memory_order_acq_rel, // 按需使用读取、写入内存屏障,如compare_and_swap
memory_order_seq_cst // 同时使用读取、写入内存屏障,比较高成本
} memory_order;
上面这段代码是C++ 20中memory order的定义,注释里简单介绍了一下各个枚举类型。memory order有一个好伙伴,经常和它一起出现,这就是原子变量(atomic variable)。下面举一个例子:
// 代码段6
#include <thread>;
#include <atomic>;
#include <cassert>;
#include <string>;
std::atomic<std::string*> ptr;
int data;
void producer(){
std::string* p = new std::string(“Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer(){
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fires
assert(data == 42); // never fires
}
int main(){
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
这段代码相当于实现了一个消息传递的逻辑,ptr是保护消息是否准备好的flag,data是消息的具体内容。当消费者读到消息已经ready的时候,就会去消费消息。我们需要保证此时消费者读到的消息数据一定是最新的,这就借助了memory order的API。代码段6 其实就是 代码段4 的更优化、更标准版本(如果我们不去讨论更复杂的情况)。
后记
本文主要是以Store Buffer和Invalidate Queue结构为依据,分析了memory order的设计。个人感觉从硬件设计的角度才能更好的理解memory order这一概念。 虽然大量依据了《Is Parallel Programming Hard, And, If So, What Can You Do About It?》,但是本文其实是有不少缺陷的。缺陷主要体现在没有考虑load-store之间的reorder。这种reorder在x86、powerPC上虽然不存在,但是在其他更乱序的硬件上是存在的。所以本文中的不少表述是不准确的,但个人认为读者可以关注于思路。 这种load-store乱序对应的硬件结构是Load Buffer或者Reorder Buffer。为什么这种乱序是有意义的呢?可以考虑一个场景,load指令没有命中cache、但之后的store指令发射时store buffer刚好满了,则load会耗时比较久,如果load可以异步等待,则可以达到更高的指令吞吐量。但由于个人水平有限,对Load Buffer或者Reorder Buffer的理解还很浅,这里就先不细写了。
参考资料:
-
《Is Parallel Programming Hard, And, If So, What Can You Do About It?》
-
https://iis-people.ee.ethz.ch/~gmichi/asocd/addinfo/Out-of-Order_execution.pdf
-
https://www.modernescpp.com/index.php/fences-as-memory-barriers
-
https://en.cppreference.com/w/cpp/atomic/memory_order
-
https://llvm.org/docs/Atomics.html
发表评论